


The super advanced voice cloning technology in Chatterbox Turbo implies that we must consider the ethics of it with seriousness and how to use it in a responsible way. Voice synthesis could be abused very easily, you can imagine illegal copying of voices, counterfeit media, scams, etc. so that is huge red flag. That is why we must be more attentive, adhere to the law, and pay attention to whether it is ethical or not, and the voice rights, the privacy of other people.
The best thing to do is to be direct; take explicit permission before you record somebody talking, make it clear that the result is synthetic and avoid applications that might mislead or even cause harm to individuals. Any organization relying on Chatterbox Turbo must draw the use rule which includes safeguards, keep the lines open when AI is used, remain transparent when it comes to the wording, and acknowledge the IP rights pertaining to the voices recorded.
Guide to running Chatterbox Turbo on Google Colab
It is far more convenient to run the tool on Google Colab; you do not need to acquire huge GPU systems; one should tap into the resources of Google and make the model run in no time. The entire configuration requires literally zero effort, meaning, few clicks, bare minimum and tech expertise, and you are prepared to generate some very good voice synths. You begin with a T4 graphic runtime; that is powerful enough to create real time speech and you can do it with your fingernails. Once you have everything up and running you would have a public URL which serves a live web page, where by you can phonate right away with any browser. The initial point of pulling the model only lasts one minute or two, after that this is in the cache and the next time one wants to start it up, this occurs very fast and the latency is never felt.
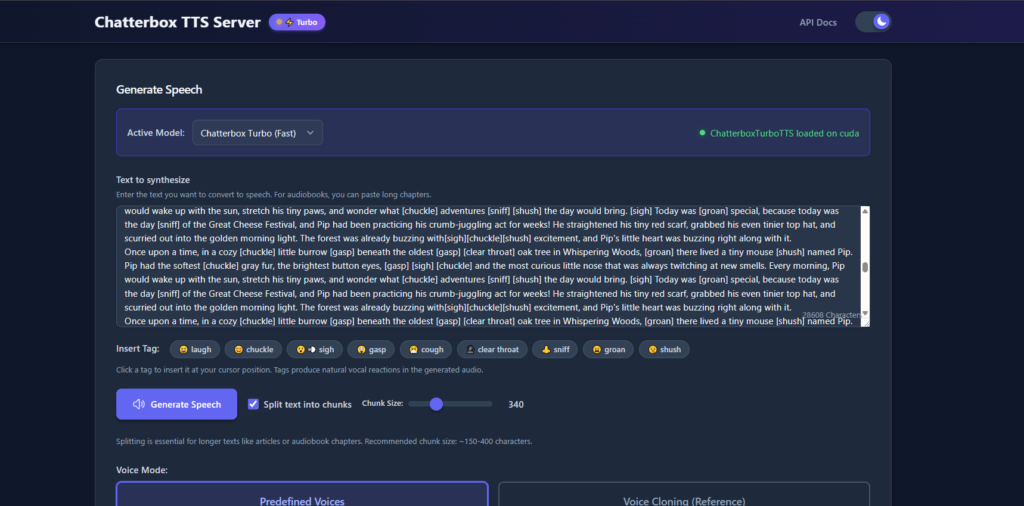
User Interface and Generating Workflow
User Interface and Generating Workflow. The Chatterbox Turbo UI is exceptionally relaxed since you can just paste your text and apply any emotional tags that you desire to and be ready to receive a pleasant voice-synth experience. You will also require reference clip; which is that of your voice. Record a WAV file (lasting no more than 30 seconds, clear sound, no background noise) so that the model could copy you to the dot.
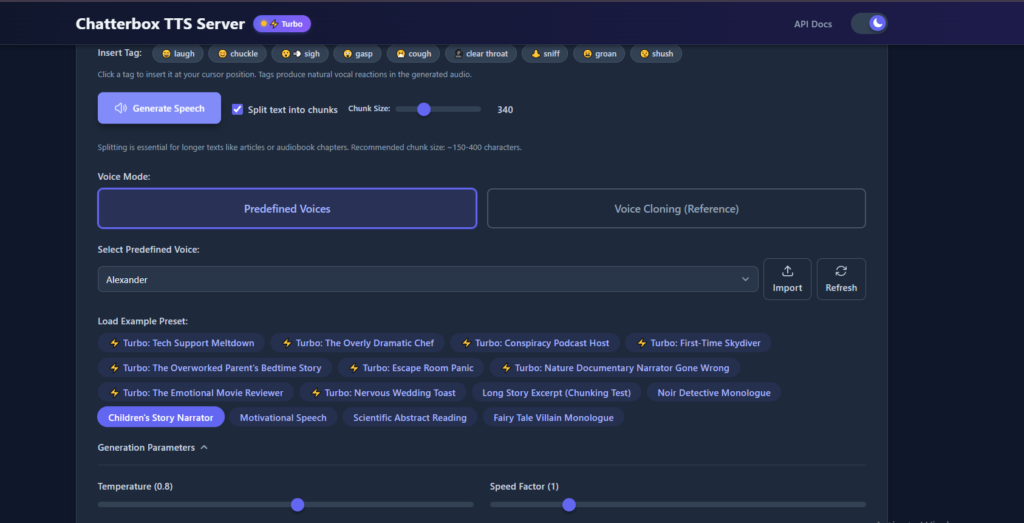
Elements and Advanced Configuration Other-Tuning
On a lot of things you can be tweaked: you can save you output as either a WAV or MP3, it can randomise a seed or temperature in order to be creative, and generally fiddle with the results to make them fit the project. Everything depends on temperature, the higher the numbers, the more the speech is spread and is wild and expressive, the lower the number, the more it is safe. The seed will keep you similar in case you desire the same output over and over.
Real Life Application and Use Case Scenario
Chatterbox Turbo has a lot of employment: podcasts, audiobooks, dubbing of movies, etc. you get the same high-quality voice on an entire series of files. Lifelike sounding speech and emotional nuance allow teachers to drop it into the lesson or develop virtual tutor or generate accessible material that can be used by visual impaired students.
Optimization and Best Practice of voice cloning
To achieve the best quality, your reference audio must be of high quality: clear, loud enough, no hissing at the background, display a variety of tones so that the clone can sound real. Recording in a low noise area and within a good microphone is also recommended as well as normalising levels to ensure a clean input the model needs to know how to learn the voice correctly.
Language Limitations and Input Format Requirements
Limitations on the Language and the Requirements of the Input Formats. It is constructed in English and when given Japanese or Chinese clips it automatically returns to English and no one is aware how it did it. That’s how it was trained. You may simply drop any common file type -MP3, WAV etc, although the WAV is preferable as it preserves the whole sound. Make the clip short, not exceeding 30 seconds and thus within the bounds and yet provide enough data to the model.
Alternative Deployment and ONNX Quantization
The model can also be run on edge devices with ONNX quantised versions outside of Colab, and is intended to be run on small edge hardware and hardware that cannot run large GPUs. The ONNX models are available in both FP16 and FP32 which is why you are able to strike a balance between the size of the model you are using, speed and voice quality.
Remarks on Ethical Concerns and Other Responsible Uses
Once again, the technology of cloning the big voice in Chatterbox Turbo requires us to consider the ethics of doing it and to do the same in a responsible manner. The voice synthesis is in danger of abuse; the privacy should be closely monitored, voice rights should be respected, and the law and ethics should be utilized.
Outlook The Future of the Open-source voice synthesis technology
The fact that Chatterbox Turbo is an open-source voice tech that is equally massive in winning over paid tools and shows that anything built by a community can lead to large successes in text-to-speech is truly impressive. It will fit more jobs as it will grow more proficient at speaking more languages, feeling emotions and be more fast.
Using Colab and ONNX help, anyone can now experiment with the most current voice AI without the need to purchase rack-mount space, or costly equipment. It is the freedom that leads to new ideas, which enrich the larger AI voice world. We do not lose ethics and intelligent use yet though we must keep smart deployment watched over in case we can use it safely and meaningfully.